
Amazon Managed Service for Apache Flink를 사용하면 스트림 처리 애플리케이션을 쉽게 구축하고 Apache Flink를 통해 스트리밍 데이터를 실시간으로 분석할 수 있습니다.
그 중 Studio notebooks를 사용하면 Apache Zeppelin 기반 노트북을 통해 스트리밍 데이터를 인터랙티브하게 분석할 수 있습니다. Apache Zeppelin은 데이터 시각화, 데이터를 파일로 내보내기, 더 쉬운 분석을 위해 출력 형식 제어 등의 기능을 포함한 분석 도구를 제공하기도 합니다.
오늘은 Studio notebooks를 사용하여 Kinesis Data Stream으로 들어오는 데이터를 분석해봅시다.
1. 준비
스트리밍 데이터를 수집할 Kinesis Data Stream을 생성합니다.

Kinesis Data Stream에 데이터를 보내기 위해 로컬 환경에서 Python 코드를 실행합니다. 다음 코드를 사용합니다.
# log.py
import datetime
import json
import random
import boto3
def get_random_data():
rand = random.randint(0, 2)
level = ['INFO', 'WARN', 'ERROR']
path = ['/v1/color/red', '/v1/error/3xx', '/v1/error/5xx']
status = [200, 304, 500]
return {
'level': level[rand],
'path': path[rand],
'status': status[rand],
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
count = 0
try:
while True:
data = get_random_data()
partition_key = str(random.randint(1, 100))
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
count += 1
except KeyboardInterrupt:
print(f'Completed sending {count} logs')
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data("demo-stream", kinesis_client)
2. 생성
Amazon Managed Service for Apache Flink 콘솔로 가서 Studio notebooks를 선택하고, Create Studio notebook을 누릅니다.

오늘은 간단한 연습을 위해 Quick create with sample code를 선택하겠습니다.

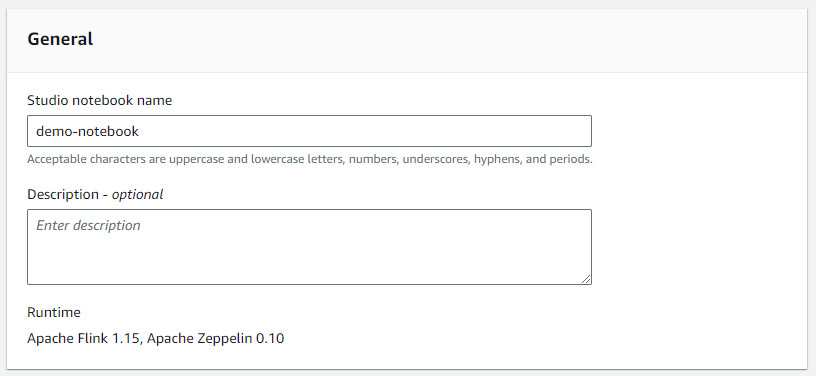
Studio notebook의 이름을 설정합니다.
Glue에서 Database를 생성한 후, 해당 Database를 선택합니다.

Create Studio notebook을 눌러 notebook을 생성합니다.

Studio notebook details에서 Edit IAM permissions를 누릅니다.

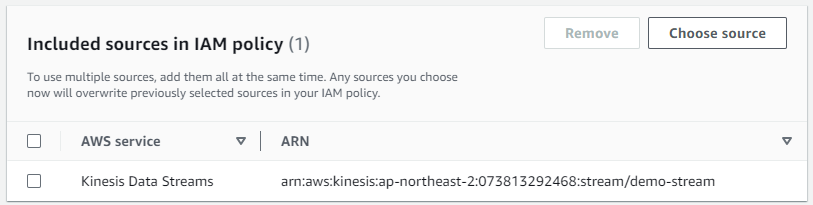
Source로 전에 생성했던 Kinesis Data Stream을 선택합니다. Save changes를 눌러 IAM policy를 수정해 Kinesis Data Stream에 접근할 수 있도록 합니다.
이제 Run을 눌러 notebook을 실행합니다. Status가 Running이 될 때까지 기다립니다.

Open in Apache Zeppelin을 누르면 Zeppelin notebook에 접속됩니다.


Examples라는 note가 이미 생성되어 있습니다. 이곳에서 작업을 진행하겠습니다.

3. 쿼리
Examples note에서는 Kinesis Data Stream이나 Kafka를 이용할 때 Table을 생성하는 예시를 보여줍니다. 이 주석을 이용하여 Table을 생성해봅시다.
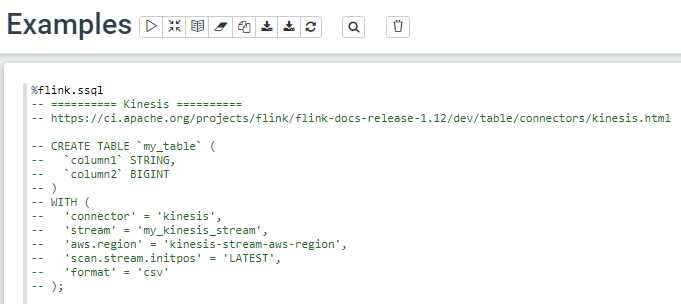
첫 번째 Paragraph를 다음과 같이 수정합니다.
첫 줄로 스트림 SQL 환경을 제공할 것을 지시하며, CREATE TABLE 명령으로 로그에 맞는 컬럼을 가진 Table을 생성합니다. Kinesis Data Stream과 연결하는 설정도 진행합니다.
%flink.ssql
CREATE TABLE demo_table (
level VARCHAR(5),
path VARCHAR(13),
status INT,
event_time TIMESTAMP
)
WITH (
'connector' = 'kinesis',
'stream' = 'demo-stream',
'aws.region' = 'ap-northeast-2',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);다 수정했다면 실행 버튼(Shift + Enter)을 누릅니다. Table이 성공적으로 생성된 것을 볼 수 있습니다.


두 번째 Paragraph는 다음과 같이 작성합니다.
첫 줄의 파라미터로 새 데이터가 도착할 때 SELECT의 출력이 지속적으로 업데이트됩니다.
%flink.ssql(type=update)
SELECT * FROM demo_table;명령어를 실행(Shift + Enter)한 후, 로그를 보내는 Python 코드도 실행합니다. Ctrl + c로 중지할 수 있습니다.
pip install boto3
python log.py686개의 로그를 보냈고, 실시간으로 Table도 업데이트된 것을 볼 수 있습니다.


설정을 통해 여러 그래프를 그릴 수 있습니다.
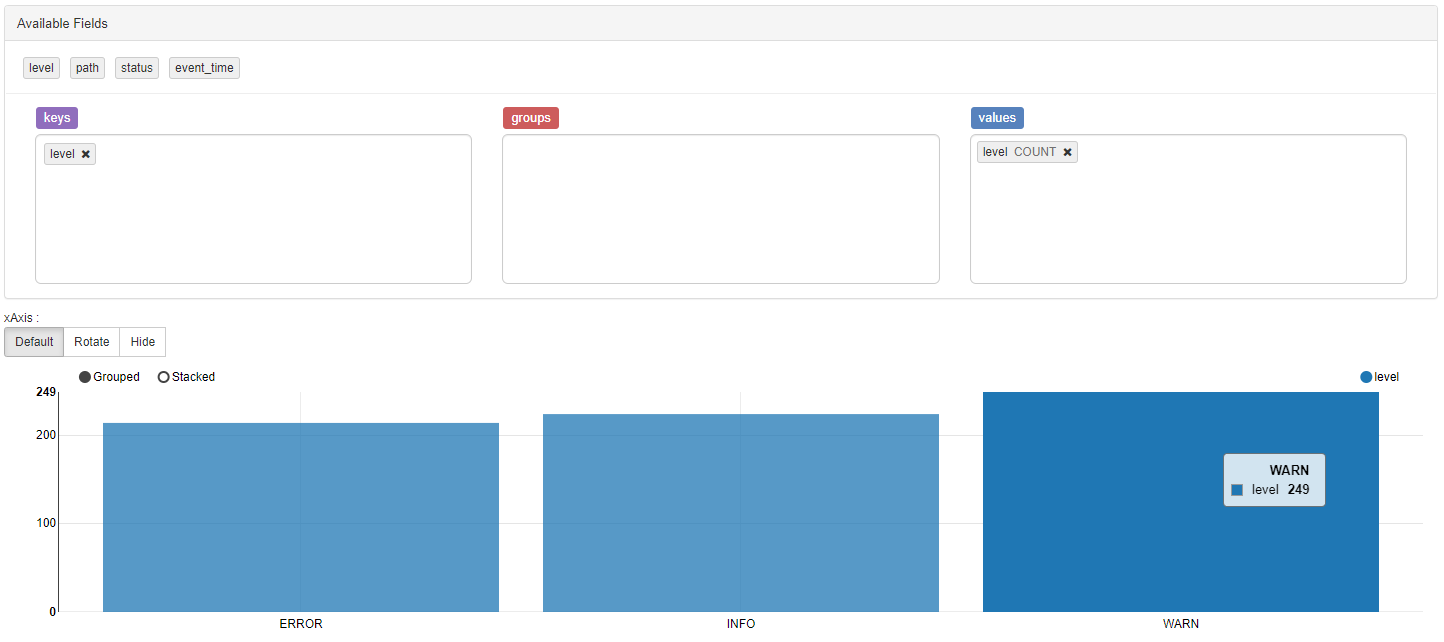

Download Data as CSV를 눌러 CSV 파일로 데이터를 다운로드 받을 수 있습니다.


다음에는 output stream도 설정해보고, 여러 쿼리도 실행해봅시다. 감사합니다!
'AWS' 카테고리의 다른 글
| [AWS] SSH 액세스 실패를 감지하여 이메일에 알리기 (2) | 2023.11.28 |
|---|---|
| [AWS] Golang Gin 이미지를 만들어서 ECR에 Push (1) | 2023.10.14 |
| [AWS] Athena에서 Table 생성부터 데이터 조회까지 (1) | 2023.10.12 |
| [AWS] RDS IAM database authentication (1) | 2023.10.11 |
| [AWS] Kinesis Agent로 Kinesis Data Stream에 로그 전송 (3) | 2023.10.10 |