
1편에 이어서 output stream을 설정해 봅시다.
[AWS] Managed Service for Apache Flink로 스트리밍 데이터 분석 - Studio notebooks (1)
Amazon Managed Service for Apache Flink를 사용하면 스트림 처리 애플리케이션을 쉽게 구축하고 Apache Flink를 통해 스트리밍 데이터를 실시간으로 분석할 수 있습니다. 그 중 Studio notebooks를 사용하면 Apache
arcozz.tistory.com
1. 준비
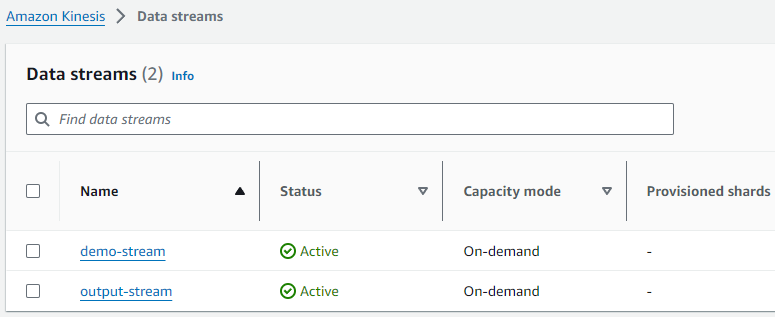
output stream을 추가적으로 생성해 줍니다.
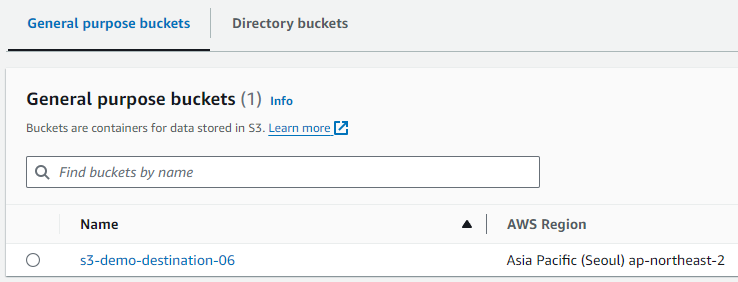
로그를 저장할 S3 Bucket도 생성해 줍니다.
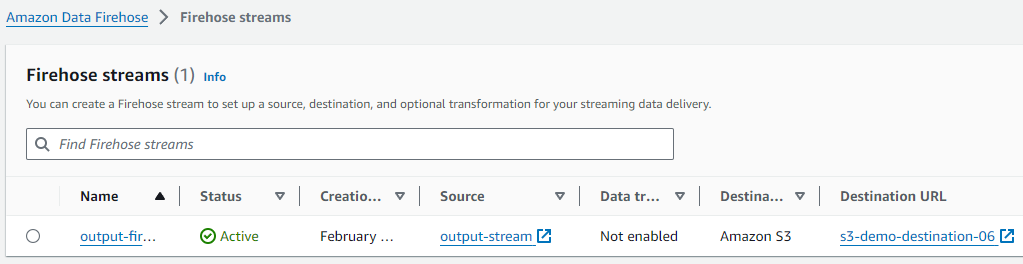
Source가 output-stream이고, Destination이 S3 Bucket인 Kinesis Data Firehose도 하나 생성해 줍니다.
2. 권한 업데이트
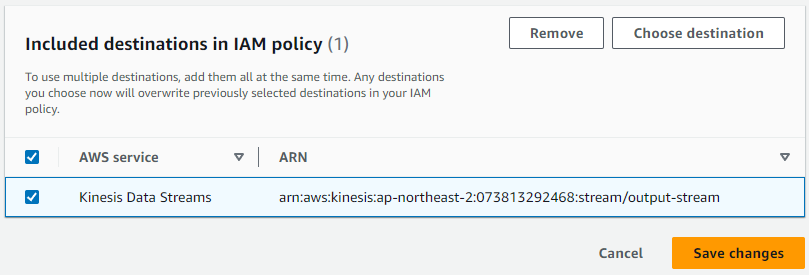
Studio notebook details에서 Edit IAM permissions를 누릅니다.
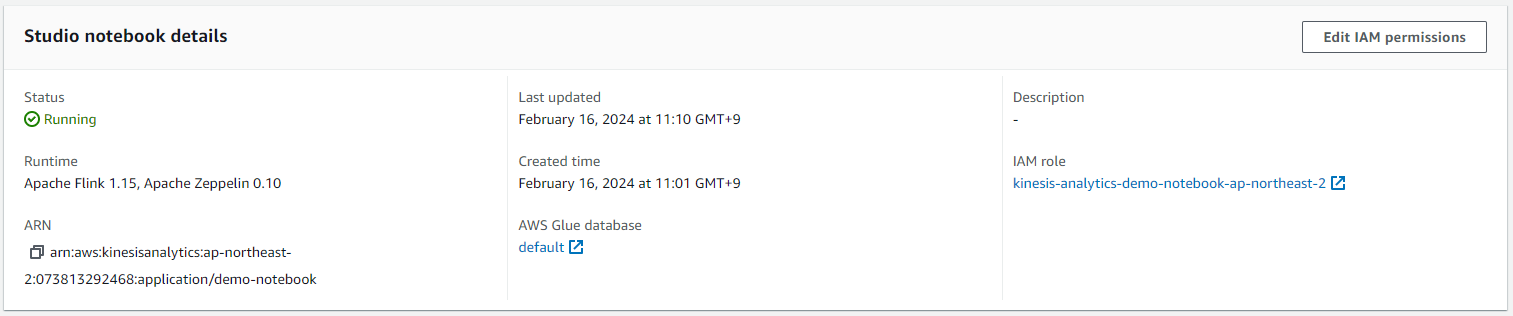
Included destinations in IAM policy에서 output-stream을 추가합니다. Save changes를 눌러 권한 업데이트를 진행합니다.
3. 쿼리
시간 관련 설정을 하기 위해 demo_table부터 다시 생성하겠습니다.(DROP TABLE을 할 때 추가 권한이 필요합니다)
추가적으로 WATERMARK를 정의하여 메시지의 지연 시간을 5초까지 허용하겠다고 설정했습니다.
WATERMARK에 대한 자세한 정보는 다음 블로그를 참고하면 좋습니다.
https://seamless.tistory.com/99
%flink.ssql
DROP TABLE IF EXISTS demo_table;
CREATE TABLE demo_table (
level VARCHAR(5),
path VARCHAR(13),
status INTEGER,
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
WITH (
'connector' = 'kinesis',
'stream' = 'demo-stream',
'aws.region' = 'ap-northeast-2',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);
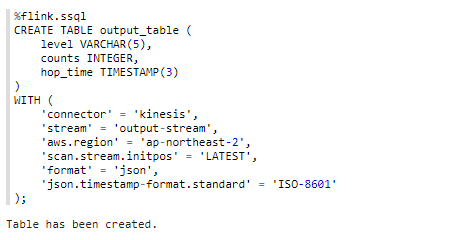
output-stream과 연결된 테이블을 생성해 줍니다. counts는 time 간격, level 당 요청 수입니다.
%flink.ssql
CREATE TABLE output_table (
level VARCHAR(5),
counts BIGINT,
hop_time TIMESTAMP(3)
)
WITH (
'connector' = 'kinesis',
'stream' = 'output-stream',
'aws.region' = 'ap-northeast-2',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);
INSERT INTO를 이용해 output_table (output-stream)에 데이터를 삽입합니다.
HOP, HOP_ROWTIME 함수를 이용하여 10초마다 결과를 업데이트하고 1분의 슬라이딩 시간대에서 결과를 계산합니다.
(첫 번째 윈도우는 00:00부터 01:00까지, 두 번째 윈도우는 00:10부터 01:10까지 데이터를 포함하고, 이런 식으로 계속 이동합니다.)
%flink.ssql(type=update)
INSERT INTO output_table
SELECT level,
COUNT(*) AS counts,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) AS hop_time
FROM demo_table
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), level;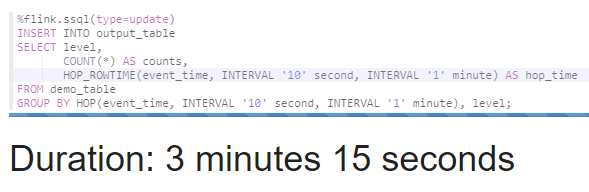
이제 다시 로깅 애플리케이션을 실행합니다. (1편 참고)
조금만 기다리면 S3로 데이터가 성공적으로 전달된 것을 볼 수 있습니다.
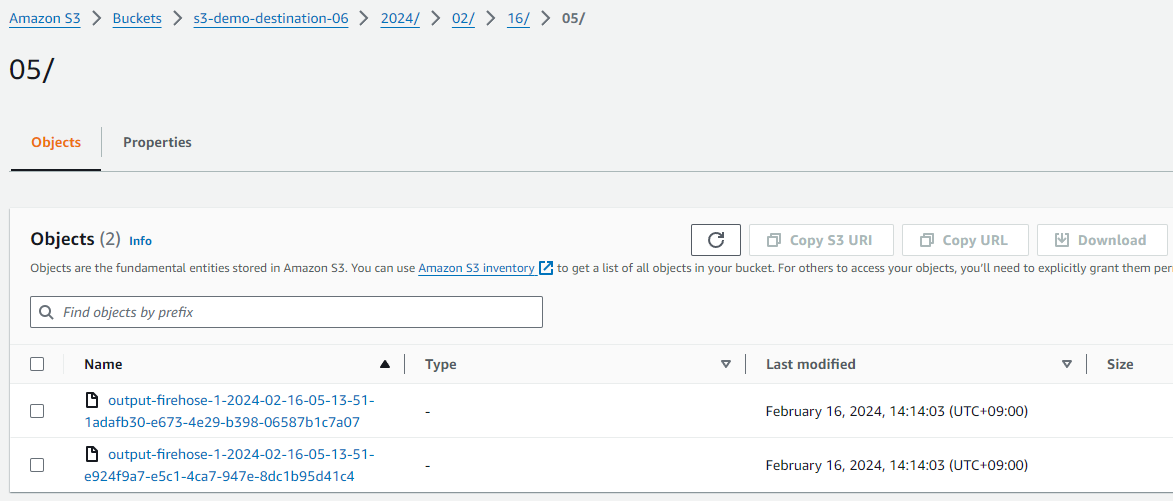
실습에서는 안 다뤘지만 PARTITIONED BY 설정까지 해주면 데이터를 더 잘 받을 것입니다.
{"level":"WARN","counts":204,"hop_time":"2024-02-16T14:13:39.999"}
{"level":"WARN","counts":410,"hop_time":"2024-02-16T14:13:49.999"}
{"level":"ERROR","counts":207,"hop_time":"2024-02-16T14:13:39.999"}
{"level":"ERROR","counts":418,"hop_time":"2024-02-16T14:13:49.999"}
{"level":"INFO","counts":223,"hop_time":"2024-02-16T14:13:39.999"}
{"level":"INFO","counts":490,"hop_time":"2024-02-16T14:13:49.999"}오늘의 글은 여기까지입니다. 감사합니다!
'AWS' 카테고리의 다른 글
| [AWS] ArgoCD Image Updater로 이미지 자동 배포 (with ECR) (4) | 2024.02.28 |
|---|---|
| [AWS] AWS Load Balancer Controller로 HTTPS가 적용된 ALB 생성하기 (0) | 2024.02.21 |
| [AWS] Terraform으로 EC2 Instance 생성하기 (0) | 2024.01.19 |
| [AWS] AWS Config로 Security group 감시하기 (0) | 2024.01.02 |
| [AWS] Github Actions로 ECS 서비스에 배포 (Blue / Green) (2) | 2023.12.31 |